


Blog
Data Agility Starts with Smart Technology Choices: How Rigid Schemas Hold You Back
- 28 July, 2025
- By Dave Cassel
In today’s data-driven world, agility isn’t just a competitive advantage—it’s a necessity. Organizations are increasingly building data hubs to break down data silos from across the enterprise, enabling better analytics, faster decision-making, and more responsive operations. But as any data leader knows, integrating data from diverse sources is no easy task.
Data sources often express similar information differently, with varying structures, vocabularies, and labels. Figuring out a common representation of all that data is a major project in itself, before you can even start to take advantage of it. The technology choices you make around how data is stored and modeled can either enable your team to move quickly or bog them down in complexity.
This post explores why rigid schemas are a poor fit for modern data hubs, and how a more flexible, layered approach to data modeling can unlock true data agility.
The Challenge of Diverse Data Sources
When building a data hub, one of the most common challenges is dealing with the diversity of incoming data. Different data sources are accessed in different ways, and they each have their own way of expressing information. Field names differ, data types vary, and even the meaning of similar-looking data can shift depending on context.
This diversity isn’t just a technical inconvenience—it’s an obstacle to creating a single, unified view of your business. Before you can analyze or make use of the data, you need to reconcile these differences. For many organizations, that means looking in different systems for subsets of data—trying to find all the puzzle pieces needed to assemble the complete data picture. Choosing to build a unified data hub means mapping fields, aligning semantics, and often transforming the data into a common format that your systems and teams can work with.
This harmonization process is essential, but it’s also time-consuming and resource-intensive. And it becomes even more complex when the underlying data sources evolve. New fields appear, formats change, or entirely new systems are added to the mix. If your data platform isn’t built to accommodate this kind of change, your team will constantly be playing catch-up.
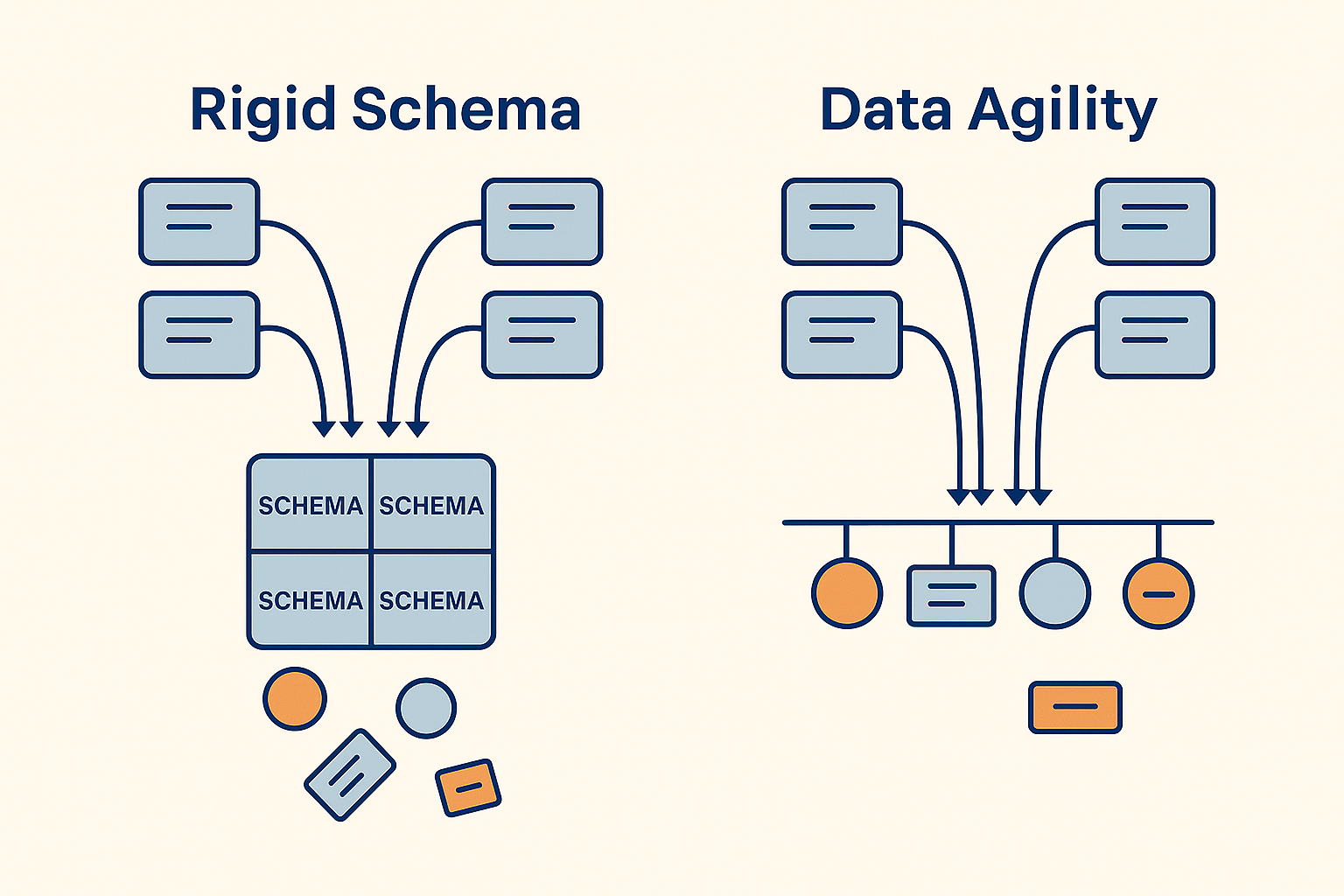
The Pitfall of Rigid Schemas
Traditional databases with a single model often rely on rigid schemas—fixed structures that define exactly what data can be stored and how it must be formatted. While this approach works well for systems with stable, predictable data structures, it becomes a major obstacle when building a data hub that needs to integrate and evolve.
Rigid schemas force teams to define the entire structure of the data up front. That means anticipating the type, cardinality, and relationships of every field before you can even begin ingesting data. This delays time-to-value and creates a bottleneck for innovation.
But in reality, not all data is equally valuable at the beginning of a project. A more agile approach is to identify a subset of the data that delivers immediate business value. Finding the key fields that support analytics, reporting, or operational decisions, then harmonizing that core data allows you to move quickly and start delivering insights that drive your business.
At the same time, it’s critical to preserve the rest of the data in a way that’s associated with the correct records and accessible for future use. Storing this supplementary information as JSON alongside the harmonized data provides a flexible, schema-light way to retain context without locking yourself into a rigid structure. As your understanding of the data grows or new use cases emerge, you can progressively enrich your schema without reengineering your entire pipeline.
This iterative approach of using a core schema and extensible raw data enables agility, adaptability, and long-term scalability.
A More Agile Approach to Data Modeling
To support agility, your data platform needs to accommodate both structure and flexibility. That means moving away from an “all-or-nothing” schema mindset and embracing an iterative approach to data modeling.
Start by defining a core schema that captures the most valuable and commonly used data elements. This schema should be designed to support a small number of initial use cases without trying to account for every possible variation or future need.
Then, instead of discarding or ignoring the rest of the data, store it in a flexible format that can be associated with the same records. JSON works well for this purpose. This allows you to retain the full context of the original data without forcing it into a rigid mold. When new requirements arise, or when deeper insights are needed, you can revisit that raw data and selectively incorporate additional fields into your harmonized model.
This approach offers several key benefits:
- Faster onboarding of new data sources: You don’t need to fully model every source before you can start using it.
- Incremental schema evolution: You can adapt your model over time as business needs change.
- Preservation of context: You retain access to the original data, which can be critical for auditing, troubleshooting, or future enrichment.
By combining a well-structured core with an easily accessible record of the upstream data, you create a data foundation that’s both stable and adaptable—ideal for the dynamic needs of modern enterprises.
Technology Selection Criteria for Data Agility
Choosing the right technology is critical to enabling data agility. Performance and scalability are important, but your platform also needs to support the evolving needs of your data and your business. The goal is to move quickly, adapt easily, and preserve flexibility as your requirements change.
Here are some key capabilities to look for when evaluating data management technologies:
- Support for semi-structured data: Look for a platform that includes native support for formats like JSON. This allows you to retain raw data alongside structured fields, preserving context without forcing premature modeling decisions.
- Extensibility and adaptability: Your platform should make it easy to add new fields, support new data types, and evolve your schema without disrupting existing pipelines or applications.
- Integration-friendly architecture: The goal of a data hub is to have one source providing data for many services. Enabling connectivity is a key component of the project. Choose technologies that offer robust APIs and connectors while supporting common data exchange formats to simplify integration with upstream and downstream systems.
- Scalability: Even while you focus your data modeling needs on the short- to medium-term, planning for the future is essential. Your technology should scale not only in terms of data volume, but also in complexity. Over time, you may add use cases, enrich your data models, and add more sources.
By prioritizing these capabilities, you’re not just choosing a tool—you’re laying the foundation for a data strategy that can grow and adapt with your organization.
Real-World Implications
The technical decision of how you approach data modeling may seem like an implementation detail, but it is central to your team's ability to move faster, respond to change, and deliver value quickly.
For example, when onboarding a new data source, a rigid schema might require weeks of upfront modeling and integration work. With a more flexible approach, you can ingest the data immediately, harmonize the most important fields, and start generating insights while preserving the rest for future use.
This agility also supports innovation. As new opportunities emerge, your team can quickly adapt the data model to support their needs without reengineering your entire pipeline. That means faster time-to-insight, lower integration costs, and a more responsive data strategy overall.
In short, data agility empowers your organization to treat data as a living asset—one that evolves with your business, rather than holding it back.
Conclusion
With any software project, there are some aspects that are worth getting right in the beginning. Adding security or accessibility to an almost-done project is much more complex than including them in your approach from the beginning. Likewise, a solid foundation to your data modeling strategy gives you the flexibility to move quickly, adapt to change, and evolve over time.
Rigid schemas and inflexible platforms slow progress. They force premature decisions, delay time-to-value, and make it harder to respond to new opportunities. By contrast, a layered, iterative approach to data modeling—harmonizing what matters now and preserving the rest for later—gives your team the tools they need to shorten time-to-value and adapt as your needs grow.
Choosing the right technology is a critical part of that journey. Look for platforms that support semi-structured data, enable schema evolution, and make integration seamless. With the right foundation, your data hub becomes more than a repository—it becomes a catalyst for innovation.
Share this post:
4V Services works with development teams to boost their knowledge and capabilities. Contact us today to talk about how we can help you succeed!



In today’s data-driven world, agility isn’t just a competitive advantage—it’s a necessity. Organizations are increasingly building data hubs to break...