





Blog
Populating an array from numbered fields
- 28 November, 2021
- By Dave Cassel
- No Comments

As we move data from other sources (often relational databases) into MarkLogic JSON, we have the opportunity to change the way data are represented. I’ve seen a pattern a few times where the incoming source repeats a field, appending a number. I’ll illustrate with a simplified example:
name,pet_name_1,pet_name2 David,Merry,Pippin Alice,Spot, Bob,Fluffy,George
When I see something like this, I represent the numbered fields as an Array. My entity definition would have two properties in this case: “Name” (a string) and “PetNames” (an array of strings).
MarkLogic’s Hub Central makes it easy to define an entity and set up a mapping to populate it. When defining the mapping, we can provide a simple XPath expression for each property. For the “Name” property, we can just give “name” as the expression. To populate the array, we have multiple properties we want to pull from. We can do this very simply:
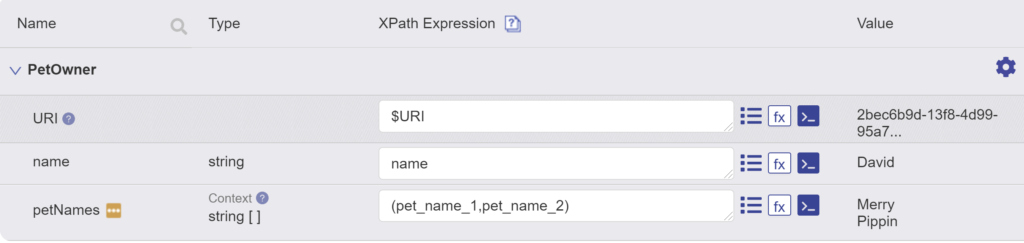
We list the property names that we want to put in the array, separating them with commas. After running the mapping step, we get this (showing just the instance portion of the entity):
{
"PetOwner": {
"name": "David",
"petNames": [
"Merry",
"Pippin"
]
}
}Looks good! Instead of a sparse table with a fixed number of pet names, we have an array that can hold an arbitrary number of them. There is something that’s not quite right though. In our sample data, Alice has just one pet. After running the load step, which converts from CSV to JSON, here’s the instance part of the document in staging:
{
"instance": {
"name": "Alice",
"pet_name_1": "Spot",
"pet_name_2": ""
}
}
Notice that although we don’t have a value for “pet_name_2”, the JSON property still exists with an empty string. This is a reasonable interpretation of CSV to JSON, but let’s see what we end up with for our final entity:
{
"PetOwner": {
"name": "Alice",
"petNames": [
"Spot",
""
]
}
}
We have an empty string in the array, which isn’t ideal. We have a couple ways to address this. We could modify the load step to eliminate the empty property or we modify the mapping step to keep the empty string out of the final entity. I like the second idea — we’ll keep the raw data with minimal changes and focus on creating the final entity the way we want.
A simple fix for this problem can be added right in the mapping XPath expression:
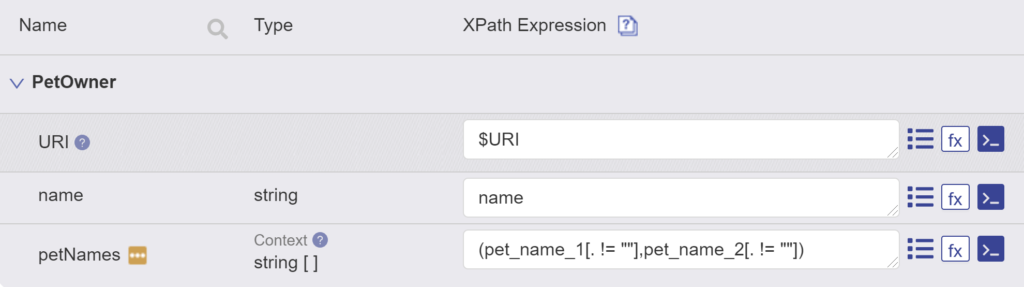
The [. != ""] in the XPath selects for values that are not empty strings, leading to a cleaner final entity:
{
"PetOwner": {
"name": "Alice",
"petNames": [
"Spot"
]
}
}


As we move data from other sources (often relational databases) into MarkLogic JSON, we have the opportunity to change the...